

干掉中介层,这家公司或带来chiplet革命!
2023-04-09 08:01:59 53
来源:内容由半导体行业观察编译自forbes ,谢谢。
人工智能终于迎来了它的 iPhone 时刻。ChatGPT 的推出引发了全行业的兴奋浪潮,人们大量关注大型预训练生成式人工智能模型,如 GPT-3、GPT-4 等。人类已冲向重大技术颠覆的边缘,新工具和功能似乎有限只能靠我们的想象。
但天下没有免费的午餐。为了真正有价值——并建立一个全世界享有技术平等的未来——运行这些模型的成本必须在未来几年内降低一个数量级,以实现微软和谷歌等公司的雄心勃勃的目标。让所有人都能使用这些新功能。
训练大型语言模型 (LLM) 和基础模型的成本相当高,据报道,用于训练单个模型的计算硬件和能源花费超过 1000 万美元。使用模型(称为推理)比我们目前依赖的其他计算工作负载的成本要高得多。相比之下,ChatGPT 的每次推理成本估计比谷歌搜索高 4 到 70 倍!
现在,相当多的注意力和资金都集中在可以提高处理这些大量新工作负载所需的计算效率的公司。总部位于圣克拉拉的 Eliyan 是一家具有潜在游戏规则改变者的小芯片初创公司,因为其互连技术可实现比目前更多的内存和更低的成本。让我们仔细看看。
Eliyan 解决了什么问题?
ChatGPT、Bard 和类似的 AI 依赖于大型语言或基础模型,这些模型在大规模 GPU 集群上进行训练并具有数千亿个参数。训练这些模型需要在单个芯片上提供更多的内存和计算能力,因此这些模型必须级联到大型 GPU 集群或 ASIC(如 Google TPU)上。虽然大多数推理处理都可以在 CPU 上运行,但像 ChatGPT 这样的 LLM 应用程序需要 8 个 NVIDIA A100 GPU 来保存模型和处理每个 ChatGPT 查询,并且加速器内存大小受到可以连接的高带宽内存 (HBM) 芯片数量的限制每个 GPU / ASIC。这就是 Eliyan 的用武之地。
“
Eliyan做什么?技术与产品
今天的芯片到芯片互连非常昂贵,并且会显著增加芯片开发计划的工程时间。Eliyan 的高性能 PHY(物理层芯片组件)技术在不影响通信性能的情况下释放了设计灵活性,更有效地连接芯片和小芯片并满足目标工作负载的需求。
NuLink PHY 是一种基于行业标准 UCIe 和 BoW 超集的小芯片互连技术,可提供与基于硅的中介层但在标准有机基板上的互连类似的带宽、功率和延迟。NuLink 通过简化系统设计降低了系统成本。更重要的是,对于生成式 AI,NuLink 增加了内存容量,从而提高了配备 HBM 的 GPU 和 ASIC 的内存密集型应用程序的性能。
Eliyan 还创建了一个名为NuGear的小芯片,将 HBM PHY 接口转换为 NuLink PHY。NuGear 小芯片允许将标准的现成 HBM 部件与 GPU 和 ASIC 一起封装在标准有机封装中,而无需任何中介层。
NuLinkX超越了小芯片通信,将 NuLink 的覆盖范围扩展了 10 倍,至少达到 20 厘米,支持通过印刷电路板 (PCB) 的芯片到芯片外部路由。NuLinkX 通过提供无与伦比的外部带宽效率来提高高性能系统的设计灵活性,帮助系统设计人员通过实现高效的处理器集群和内存扩展来针对高性能工作负载进行优化。
用于 HBM 互连的 NuLink
NVIDIA、谷歌、AMD、英特尔都利用系统设计将 ASIC(例如 GPU)连接到 HBM 以处理 AI 工作负载。今天的芯片设计人员使用先进的封装将 HBM与其他 ASIC 集成,有效地定义了一组定义明确的高性能、昂贵的互连,从而实现了逻辑和存储器之间的快速通信。它可以工作,但它很僵硬——使用硅中介层,考虑到处理技术的尺寸限制,我们今天每个 SOC 只能使用 6 个 HBM3 块。
Eliyan 的 NuLink 消除了对此类高级中介层的需求,通过有机基板将 HBM 芯片直接连接到 ASIC。
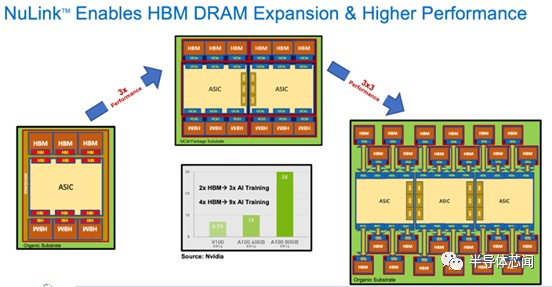
NVIDIA 提供两种型号的 A100 GPU,具有 40 GB 和 80GB 的 HBM,并表明更大的内存提供了 3 倍的性能优势。
利用 NuLink,可以将 HBM的数量增加两倍,达到 160 GB。假设 AI 训练中内存优势的线性缩放,采用 NuLink 再次将性能提高三倍。
由于 NuLink 无需中介层即可连接小芯片,因此封装的尺寸可能会增加到超过光罩的尺寸。可以想象一个具有 24 个 HBM 堆栈或 384 GB 的三 ASIC 封装,如上所示。如果假设与 NVIDIA 享受从 40 GB 到 80 GB 相同的性能扩展,那么您可能会实现 9 倍的性能提升,假设 3 个 ASIC 可以处理数学而不会受到计算限制。如今,ChatGPT 受内存限制,而非计算限制。
虽然拥有更多内存来训练大型语言模型可能会受到高达 10 倍加速的影响,但推理处理也可以通过减少保存模型所需的加速器占用空间而受益,因为人们可以使用更少的 ASIC 处理大型模型。
GPT-3 拥有 1750 亿个参数,是一个巨大的模型,需要超过 700 GB 的高性能内存才能运行。每个 GPU 80 GB,这意味着至少需要 8 个 GPU 才能在 ChatGPT 上运行推理。如果 GPU/ASIC 利用率低下,那么数量较少且内存较多的芯片可以使用较少的 GPU 运行推理查询,从而大规模节省数百万美元。计算集群的减少或简化也将转化为更具可持续性的基础设施。一个更大的基于 Eliyan 的系统组合可以取代多达 10 个单独的 A100。更少的聚合材料、减少能量(POD 和耗散)以及空间是次要的,但可能是需要考虑的重要因素。
结论
Eliyan 消除了对先进封装的需求,例如小芯片设计中的硅中介层及其所有相关的限制和复杂性;因此,可能会赢得基于其 PHY 技术的客户部署,从而降低成本、提高产量并缩短芯片上市时间。此外,NVIDIA、英特尔、AMD 和谷歌等公司可以授权 NuLink IP,或从 Eliyan 购买 NuGear 小芯片,以消除硅中介层尺寸限制带来的性能瓶颈,并使他们能够实现更高性能的 AI 和 HPC SoC 。
我们相信 Eliyan 已经在 chiplet 世界中找到了一个可以变成富矿的利基市场。
本文作者可以追加内容哦 !